

C++ STL Cheatsheet (বাংলায়)- সহজভাবে ও দ্রুত রিভিশনের জন্য
STL মানে কী?
STL এর পূর্ণরূপ হলো Standard Template Library। এটি C++ এর একটি শক্তিশালী লাইব্রেরি যেখানে আগে থেকেই তৈরি করা অনেক দরকারি ডাটা স্ট্রাকচার ও অ্যালগরিদম আছে। STL ব্যবহার করলে আলাদা করে stack, queue, map, sort ইত্যাদি নিজে কষ্ট করে সব কোড লেখা লাগে না। তাই কম কোডে দ্রুত ও সহজভাবে কোড লেখা যায়। কম্পিটিটিভ প্রোগ্রামিং এবং ইন্টারভিউতে STL জানা খুবই গুরুত্বপূর্ণ।
এই লেখাটি মূলত দুই ধরনের পাঠকের জন্য তৈরি করা হয়েছে। যারা আগে থেকেই STL জানে, তাদের জন্য এটি একটি রিভিশন চিটশিট। আর যারা নতুন, তাদের জন্য এটি হতে পারে লার্নিং গাইড। এইখান থেকে দেখে দেখে প্রাকটিস করলে আশা করতে পারি তারা stl নিয়ে সমূহ ধারণা রাখবে।
তো চলুন শুরু করি আমাদের লার্নিং।
1) vector — Dynamic Array
ভেক্টর অনেকটা অ্যারের মতোই কাজ করে, কারণ এতে ইনডেক্স ব্যবহার করে ডাটা রাখা ও নেওয়া যায়। অর্থাৎ অ্যারের মতোই v[0], v[1] দিয়ে মান ব্যবহার করা সম্ভব। তবে ভেক্টর সাধারণ অ্যারের চেয়ে বেশি শক্তিশালী, কারণ এর সাইজ প্রোগ্রাম চলার সময় নিজে থেকেই বাড়ে বা কমে। অ্যারের ক্ষেত্রে সাইজ আগে থেকে নির্দিষ্ট করে দিতে হয়, কিন্তু ভেক্টরে সেটা লাগে না। এই কারণে ভেক্টরকে বলা যায় একটি ডাইনামিক অ্যারে, যা কোডে বাবহার এর ক্ষেত্রে অ্যারের চেয়ে বেশি সুবিধাজনক।

Create / Push / Pop
vector<int>, Push এবং Pop হলো ভেক্টরের সবচেয়ে বেশি ব্যবহার হওয়া তিনটি মৌলিক কাজ। একটা লাগে ভেক্টর ডিক্লেয়ার করতে একটা লাগে ভেক্টর কিছু রাখতে আরেকটা লাগে ডিলিট করতে।
১। vector<int>
vector<int> এইটা দিয়ে মুলত একটি খালি ভেক্টর তৈরি হয়, যেখানে পরে ডাটা রাখা যাবে।
vector<int> v; // Create: খালি ভেক্টর তৈরি
২।push_back()
push_back() ভেক্টরের শেষের দিকে নতুন একটি নতুন ঘর তৈরি করে। প্রতিবার এটি ব্যবহার করলে ভেক্টরের সাইজ ১ করে বেড়ে যায়। যেমন: এখানে খালি ভেক্টরটিতে 1 সাইজ বেড়ে 10 ওই ঘরে বসবে।
v.push_back(10);
৩। pop_back()
pop_back() ব্যবহার করা হয় ভেক্টরের শেষের উপাদানটি মুছে ফেলার জন্য।এখানে pop_back() কল করার পরে ভেক্টরে থাকবে {10, 20}। এই ফাংশন ব্যবহার করলে ভেক্টরের সাইজ ১ করে কমে যায়।
খেয়াল রাখতে হবে, ভেক্টর খালি থাকলে pop_back() ব্যবহার করা ঠিক নয়।
vector<int> v = {10, 20, 30};
v.pop_back(); // 30 মুছে যাবে
প্রশ্ন ১: তো এই কোডটার আউটপুট হবে?
vector<int> v;
v.push_back(10);
v.push_back(20);
v.pop_back();
আউটপুট: 10
Size / Access
১। size()
size() ব্যবহার করা হয় ভেক্টরের মোট কয়টি উপাদান আছে তা জানার জন্য। এখানে n এর মধ্যে ভেক্টরের বর্তমান সাইজ সংরক্ষণ হয়।
int n = v.size();
২। v[0]
v[0] এভাবে ইনডেক্স ব্যবহার করে vector এর ইনডেক্স এক্সেস করা হয়। এটি দ্রুত কাজ করে, কিন্তু ইনডেক্স ভুল হলে কোনো সতর্কবার্তা দেয় না।
int x = v[0];
৩। at()
at() ফাংশন ব্যবহার করলে ইনডেক্স ভুল হলে প্রোগ্রাম নিজে থেকে error দেখায়।
তাই নতুনদের জন্য এটি তুলনামূলক নিরাপদ।
int y = v.at(0);
সংক্ষেপে, size() দিয়ে সাইজ জানা হয়, [] দ্রুত কিন্তু ঝুঁকিপূর্ণ, আর at() নিরাপদ কিন্তু একটু ধীর।
int n = v.size();
int x = v[0]; // no bounds check
int y = v.at(0); // bounds check
Initialize
ভেক্টর Initialize মানে হলো, শুরুতেই ভেক্টরের ভিতরে কী থাকবে তা নির্ধারণ করে দেওয়া।
১। vector<int> a(size)
vector<int> a(value) এই লাইনে ৫ সাইজের একটি ভেক্টর তৈরি হয়, যেখানে সব মান শুরুতে ০ থাকে। অর্থাৎ: {0, 0, 0, 0, 0}
vector<int> a(5); // 5 zeros
২। vector<int> b(size, value)
vector<int> b(5, 7) এখানে ৫ সাইজের একটি ভেক্টর তৈরি হয় এবং সব জায়গায় ৭ বসে যায়।
অর্থাৎ: {7, 7, 7, 7, 7}
vector<int> b(5, 7); // 5 times 7
৩। vector<int> c = {1,2,3}
vector<int> c = {1,2,3} এইভাবে সরাসরি নিজের মতো করে মান দিয়ে ভেক্টর তৈরি করা যায়।
এতে ভেক্টরের ভিতরে থাকবে: {1, 2, 3}
vector<int> c = {1,2,3};
সংক্ষেপে, Initialize দিয়ে শুরুতেই ভেক্টরের সাইজ ও মান নির্ধারণ করা হয়।
Iterate
ভেক্টরের প্রতিটি index এ যাওয়া এবং এর ভ্যালু প্রিন্ট করার জন্য আমরা সাধারণত লুপ ব্যবহার করি।
১. সাধারণ লুপ: এখানে আমরা ইনডেক্স i ব্যবহার করছি। v.size() সাধারণত unsigned int রিটার্ন করে, তাই সতর্কতা এড়ানোর জন্য (int) কাস্টিং ব্যবহার করা ভালো অভ্যাস। যদি ইনডেক্স পজিশন জানার দরকার হয়, তবে এই পদ্ধতিটি ব্যবহার করা হয়।
২. রেঞ্জ-বেসড লুপ: এটি আধুনিক C++ এর ফিচার। এটি দেখতে অনেক পরিষ্কার এবং ছোট। এখানে লুপটি ভেক্টর v এর প্রতিটি উপাদানকে সরাসরি x এর মধ্যে নিয়ে আসে। যদি ইনডেক্স নিয়ে কাজ করার দরকার না থাকে, তবে এটি ব্যবহার করাই উত্তম।
// ১. সাধারণ for লুপ (Traditional For Loop)
for (int i = 0; i < (int)v.size(); i++){
cout << v[i] << " ";
}
// ২. রেঞ্জ-বেসড for লুপ (Range-based For Loop)
for (int x : v){
cout << x << " ";
}
Sort / Reverse
প্রোগ্রামিংয়ে ডাটা সাজানো (Sorting) এবং উল্টানো (Reversing) খুবই সাধারণ কাজ। STL ব্যবহার করে এটি এক লাইনেই করা যায়। এই ফাংশনগুলো ব্যবহার করার জন্য কোডের শুরুতে #include <algorithm> থাকতে হয়। তবে #include <bits/stdc++.h> বাবহার করলে ওইটা আর লাগে না।
// ১. ছোট থেকে বড় সাজানো (Ascending Sort)
sort(v.begin(), v.end());
// ২. ভেক্টর উল্টে দেওয়া (Reverse)
reverse(v.begin(), v.end());
ব্যাখ্যা:
Sort: sort() ফাংশনটি ভেক্টরের শুরু (begin) থেকে শেষ (end) পর্যন্ত সব উপাদানকে ছোট থেকে বড় ক্রমানুসারে সাজিয়ে ফেলে। এর টাইম কমপ্লেক্সিটি O(N\logN), যা খুবই ইফিশিয়েন্ট।
Reverse: reverse() ফাংশনটি ভেক্টরের উপাদানগুলোর ক্রম পুরো উল্টে দেয়। অর্থাৎ প্রথম উপাদান চলে যায় শেষে, আর শেষেরটা প্রথমে।
বড় থেকে ছোট সাজাবেন কীভাবে?
সাধারণ sort ফাংশন ছোট থেকে বড় সাজায়। যদি বড় থেকে ছোট (Descending) সাজাতে হলে, তবে greater<int>() অথবা রিভার্স ইটারেটর ব্যবহার করা হয়।
// পদ্ধতি ১: কম্প্যারেটর ব্যবহার করে
sort(v.begin(), v.end(), greater<int>());
// পদ্ধতি ২: রিভার্স ইটারেটর ব্যবহার করে
sort(v.rbegin(), v.rend());
Unique (remove duplicates after sort)
STL-এ সরাসরি ডুপ্লিকেট ডিলিট করার কোনো একক ফাংশন নেই। তবে sort, unique এবং erase- এই তিনটির সমন্বয়ে সহজেই ইউনিক ভ্যালুগুলো রাখা যায়। একে বলা হয় Erase-Remove Idiom.
// ১. প্রথমে সর্ট করতে হবে (বাধ্যতামূলক)
sort(v.begin(), v.end());
// ২. ইউনিক ও ইরেজ একসঙ্গে ব্যবহার
v.erase(unique(v.begin(), v.end()), v.end());
কেন এভাবে কাজ করে?
Sort: unique ফাংশনটি শুধুমাত্র পাশাপাশি থাকা ডুপ্লিকেট ভ্যালুগুলো সরাতে পারে। তাই আগে ভেক্টরটি সর্ট করে একই ভ্যালুগুলোকে পাশাপাশি আনতে হয়।
Unique: এটি ভেক্টরের ইউনিক উপাদানগুলোকে শুরুতে নিয়ে আসে এবং ডুপ্লিকেটগুলোকে শেষে পাঠিয়ে দেয়। এটি একটি ইটারেটর রিটার্ন করে যা নির্দেশ করে ইউনিক অংশটি কোথায় শেষ হয়েছে।
Erase: unique করার পর শেষের অংশে যে "গার্বেজ" বা ডুপ্লিকেট ভ্যালুগুলো থাকে, erase ফাংশন দিয়ে সেগুলো মেমোরি থেকে মুছে ফেলা হয়।
উদাহরণ:
ইনপুট: {2, 1, 2, 5, 1, 5}
সর্ট করার পর: {1, 1, 2, 2, 5, 5}
ইউনিক ও ইরেজ করার পর: {1, 2, 5}
2) iterator — Pointer-like Tool
ইটারেটর (Iterator) অনেকটা পয়েন্টারের মতো কাজ করে। এটি ভেক্টরের কোনো একটি উপাদানের মেমোরি অ্যাড্রেস বা অবস্থান নির্দেশ করে। ভ্যালু পাওয়ার জন্য আমাদের সেই অ্যাড্রেসটিকে Dereference করতে হয়।
begin/end
vector<int> v = {3, 1, 2};
// প্রথম উপাদানের ইটারেটর নেওয়া
auto it = v.begin(); // points to '3'
// ভ্যালু প্রিন্ট করা (Dereference)
cout << *it << "\n"; // Output: 3
বিস্তারিত ব্যাখ্যা:
১. v.begin(): এটি ভেক্টরের প্রথম উপাদানটিকে (0-th index) পয়েন্ট করে।
২. v.end(): এটি ভেক্টরের শেষ উপাদানের ঠিক পরের একটি কাল্পনিক বা খালি জায়গাকে পয়েন্ট করে। এটি লুপ থামানোর কন্ডিশন হিসেবে বেশি ব্যবহৃত হয়।
৩. auto: ইটারেটরের টাইপ অনেক বড় হয় (vector<int>::iterator), তাই বারবার এত বড় টাইপ না লিখে auto কিওয়ার্ড ব্যবহার করা হয়। কম্পাইলার তখন নিজে থেকেই টাইপ বুঝে নেয়।
৪. *it: ইটারেটর it শুধুমাত্র অ্যাড্রেস ধরে রাখে। সেই অ্যাড্রেসের ভেতরের মান বা ভ্যালু পাওয়ার জন্য ইটারেটরের আগে * (Asterisk) চিহ্ন ব্যবহার করতে হয়।
Iterator loop
আমরা আগে ইনডেক্স (i) এবং রেঞ্জ-বেসড (x) লুপ দেখেছি। এখন দেখব কীভাবে সরাসরি ইটারেটর ব্যবহার করে লুপ চালানো যায়।
for (auto it = v.begin(); it != v.end(); ++it){
cout << *it << " ";
}
ব্যাখ্যা:
১. শুরু (v.begin()): লুপটি ভেক্টরের প্রথম উপাদান থেকে শুরু হয়।
২. শর্ত (it != v.end()): যতক্ষণ না ইটারেটরটি v.end()-এ পৌঁছাচ্ছে (অর্থাৎ ভেক্টরের সীমানা পার না হচ্ছে), ততক্ষণ লুপ চলবে।
৩. ইনক্রিমেন্ট (++it): প্রতি ধাপে ইটারেটর এক ঘর করে সামনে আগায়।
৪. ভ্যালু (*it): *it দিয়ে ওই পজিশনের মান প্রিন্ট করা হয়।
3) pair — Two values
পেয়ার (Pair) হলো STL এর একটি খুব সাধারণ কিন্তু কাজের কন্টেইনার। এটি দুটি ভিন্ন বা একই ধরনের ডাটাকে একসাথে জোড়া হিসেবে রাখে।
সাধারণত গ্রাফের কো-অর্ডিনেট
(x, y) বা কোনো নাম ও তার রোল নম্বর একসঙ্গে রাখতে এটি ব্যবহার করা হয়।
// ১. পেয়ার ডিক্লেয়ার ও মান নির্ধারণ
pair<int, int> p = {2, 5};
// ২. মান এক্সেস করা (Access)
cout << p.first << " " << p.second << "\n"; // Output: 2 5
// ৩. অটো টাইপ ডিডাকশন (make_pair)
auto q = make_pair("Labib", 10);
ব্যাখ্যা:
১. pair<type1, type2>: পেয়ার তৈরি করার সময় দুটি ডাটা টাইপ বলে দিতে হয়। এখানে আমরা দুটি int নিয়েছি।
২. .first / .second: পেয়ারের প্রথম উপাদানটি পেতে .first এবং দ্বিতীয়টি পেতে .second ব্যবহার করা হয়। ৩. make_pair(): এটি ব্যবহার করলে আলাদা করে টাইপ উল্লেখ করতে হয় না, কম্পাইলার স্বয়ংক্রিয়ভাবে টাইপ বুঝে নেয়। উপরের উদাহরণে q একটি pair<string, int> হিসেবে তৈরি হয়েছে।
4) list — Doubly Linked List
list হলো C++ এর বিল্ট-ইন Doubly Linked List। ভেক্টরের সাথে এর মূল পার্থক্য হলো, list-এর মাঝখানে বা শুরুতে কোনো ডাটা যোগ (insert) বা ডিলিট (erase) করা খুব দ্রুত হয়। কিন্তু এর বড় অসুবিধা হলো, এতে v[i] এর মতো সরাসরি ইনডেক্স দিয়ে এক্সেস করা যায় না (No Random Access)।
list<int> l = {1, 2, 3};
// ১. দুই পাশে ডাটা যোগ করা
l.push_front(0); // শুরুতে যোগ: {0, 1, 2, 3}
l.push_back(4); // শেষে যোগ: {0, 1, 2, 3, 4}
// ২. ইটারেটর মুভ করা (Random Access নেই)
auto it = l.begin();
advance(it, 2); // ইটারেটরকে ২ ঘর সামনে নেওয়া (0 -> 1 -> 2)
// ৩. মাঝখানে ইনসার্ট করা
l.insert(it, 99); // 2 এর আগে 99 বসবে: {0, 1, 99, 2, 3, 4}
// ৪. ভ্যালু দিয়ে রিমুভ করা
l.remove(2); // লিস্টের সব '2' মুছে যাবে
কেন ব্যবহার করা হয়?
সুবিধা: যদি প্রোগ্রামে প্রচুর insert এবং delete অপারেশন করতে হয় (বিশেষ করে মাঝখানে বা শুরুতে), তবে list ব্যবহার করা ভেক্টরের চেয়ে অনেক বেশি ইফিশিয়েন্ট।
অসুবিধা: নির্দিষ্ট কোনো উপাদানে যেতে হলে লুপ চালিয়ে বা advance ব্যবহার করে যেতে হয়, যা সময়সাপেক্ষ।
5) stack — LIFO
স্ট্যাক (Stack) কাজ করে LIFO (Last In, First Out) নীতিতে। অর্থাৎ, সবার শেষে যে উপাদানটি ঢোকানো হয়, বের করার সময় সেটিই
.webp
)
সবার আগে বের হয়। একে একটি প্লেটের স্তূপের সাথে তুলনা করা যেতে পারে—সবার ওপরের প্লেটটিই কেবল নেওয়া যায় এবং নতুন প্লেট রাখতে হলে ওপরের দিকেই রাখতে হয়।
stack<int> st;
// ১. ডাটা রাখা (Push)
st.push(10);
st.push(20); // ২০ এখন সবার ওপরে
// ২. ওপরের ডাটা দেখা (Top)
cout << st.top() << "\n"; // Output: 20
// ৩. ডাটা বের করা (Pop)
st.pop(); // ২০ মুছে যাবে, এখন টপ হলো ১০
// ৪. খালি কি না চেক করা (Empty)
cout << st.empty() << "\n"; // 0 (False, কারণ ১০ আছে)
স্ট্যাকে st[i] বা মাঝখান থেকে কোনো ডাটা এক্সেস করা যায় না।
সর্বদা শুধু Top বা ওপরের উপাদানটি নিয়েই কাজ করা যায়।
pop() ফাংশন শুধু ওপরের উপাদানটি ডিলিট করে, কিন্তু সেটি রিটার্ন করে না।
6) queue — FIFO
কিউ (Queue) কাজ করে FIFO (First In, First Out) নীতিতে। অর্থাৎ, "আগে আসলে আগে পাবেন" ভিত্তিতে। টিকিট কাউন্টার বা ব্যাংকের লাইনে যেমন যে সবার আগে আসে সে সবার আগে সেবা পায়, কিউ-ও ঠিক তেমনই কাজ করে।
queue<int> q;
// ১. ডাটা রাখা (Push)
q.push(10); // লাইনে প্রথম ব্যক্তি ১০
q.push(20); // ১০ এর পেছনে দাঁড়াল ২০
// ২. সামনের ডাটা দেখা (Front)
cout << q.front() << "\n"; // Output: 10 (সবার আগে ১০ ঢুকেছিল)
// ৩. ডাটা বের করা (Pop)
q.pop(); // সামনের ১০ বের হয়ে যাবে, এখন সামনে ২০
// ৪. পেছনের ডাটা দেখা (Back)
cout << q.back() << "\n"; // Output: 20
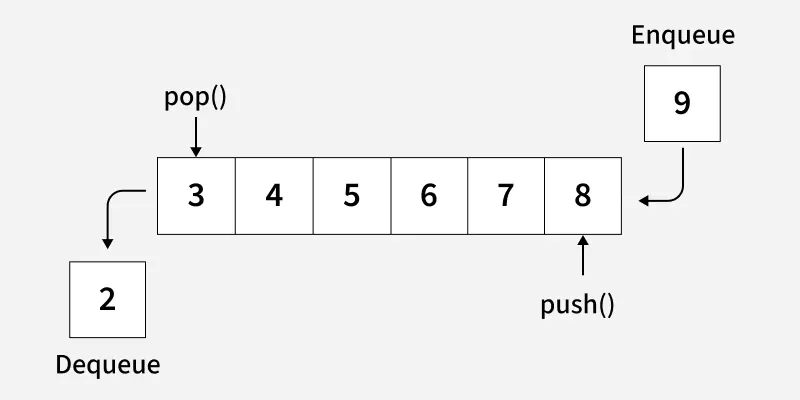
স্ট্যাক বনাম কিউ:
Stack: শেষটা আগে বের হয় (LIFO - Last In First Out)।
Queue: প্রথমটা আগে বের হয় (FIFO - First In First Out)।
কিউ-তেও স্ট্যাকের মতো মাঝখানের কোনো উপাদান সরাসরি (q[i]) এক্সেস করা যায় না।
7) deque — Double-ended Queue
deque এর পূর্ণরূপ হলো Double Ended Queue। stack আমরা শুধু শেষে (back) দ্রুত ডাটা যোগ বা বিয়োগ করতে পারি, কিন্তু শুরুতে (front) করতে গেলে অনেক সময় লাগে। deque- তে আমরা শুরু এবং শেষ—উভয় দিকেই O(1) বা খুব দ্রুত সময়ে ডাটা যোগ ও মুছতে পারি।
deque<int> dq;
// ১. দুই পাশে ডাটা যোগ করা
dq.push_front(1); // শুরুতে ১ যোগ -> {1}
dq.push_back(2); // শেষে ২ যোগ -> {1, 2}
// ২. দুই পাশ থেকে ডাটা মুছে ফেলা
dq.pop_front(); // প্রথম উপাদান (1) মুছে যাবে -> {2}
dq.pop_back(); // শেষ উপাদান (2) মুছে যাবে -> {}
কেন ব্যবহার করা হয়?
স্লাইডিং উইন্ডো (Sliding Window) প্রবলেম বা এমন কোনো পরিস্থিতিতে যেখানে দুই প্রান্ত দিয়েই ডাটা ঢোকানো বা বের করা প্রয়োজন, সেখানে deque সবচেয়ে ভালো অপশন। এতে ভেক্টরের মতো dq[i] বা র্যান্ডম এক্সেসও করা যায়।
8) priority_queue — Heap
সাধারণ কিউতে (Queue) যে আগে আসে সে আগে বের হয়। কিন্তু Priority Queue-তে যে উপাদানের মান বা গুরুত্ব (Priority) বেশি, সে সবার আগে থাকে। অর্থাৎ, এটি একটি অটোমেটেড সর্টেড লাইনের মতো কাজ করে। ইন্টারনালি এটি Heap ডাটা স্ট্রাকচার ব্যবহার করে তৈরি।
Max-heap (default)
C++ STL-এ priority_queue বাই ডিফল্ট Max-heap হিসেবে কাজ করে। এর মানে হলো, আপনি যে অর্ডারে ডাটা ইনপুট দেন না কেন, top() বা সবার ওপরে সবসময় সবচেয়ে বড় সংখ্যাটি থাকবে।
priority_queue<int> pq;
pq.push(5);
pq.push(1);
pq.push(10);
// সবার ওপরে বড় সংখ্যাটি থাকবে
cout << pq.top() << "\n"; // Output: 10
// বড় সংখ্যাটি বের করে দিলাম
pq.pop(); // ১০ মুছে যাবে, এখন টপ হবে ৫
Min-heap
যদি সবচেয়ে ছোট সংখ্যাটি সবার ওপরে থাকে, তবে Min-heap তৈরি করতে হয়। এর ডিক্লারেশন সিনট্যাক্সটি একটু আলাদা, তাই এটি মুখস্ত রাখা ভালো।
// Min-heap ডিক্লারেশন
priority_queue<int, vector<int>, greater<int>> pqmin;
pqmin.push(5);
pqmin.push(1);
pqmin.push(10);
// সবার ওপরে ছোট সংখ্যাটি থাকবে
cout << pqmin.top() << "\n"; // Output: 1
কেন ব্যবহার করা হয়?
যখন সবসময় সবচেয়ে বড় বা সবচেয়ে ছোট উপাদানটি দ্রুত (O(1))দরকার হয়। আবার এখানে নতুন ডাটা রাখা (push) এবং বের করা (pop) উভয়েই O(logN) সময় নেয়, যা বারবার সর্ট করার চেয়ে অনেক বেশি ইফিশিয়েন্ট।
9) set — Sorted Unique
set হলো এমন একটি কন্টেইনার যার দুটি প্রধান বৈশিষ্ট্য: ১. উপাদানগুলো সবসময় ছোট থেকে বড় (Sorted) অর্ডারে থাকে।২. কোনো ডুপ্লিকেট বা একই মান একাধিকবার থাকে না।ইন্টারনালি এটি Balanced Binary Search Tree (Red-Black Tree) ব্যবহার করে, তাই অপারেশনগুলো খুব দ্রুত (O(log N)) হয়।
set<int> s;
set<int> s;
s.insert(5); // {5}
s.insert(1); // {1, 5} (অটো সর্ট হয়ে গেছে)
s.insert(5); // ইগনোর হবে, কারণ ৫ আগেই আছে
// s এর বর্তমান অবস্থা: {1, 5}
Find / Erase
কোনো উপাদান খুঁজতে find() ব্যবহার করা হয়। এটি একটি ইটারেটর রিটার্ন করে।
auto it = s.find(1); // ১ খোঁজা হচ্ছে
if (it != s.end()) {
// যদি পাওয়া যায় (অর্থাৎ ইটারেটর শেষ পর্যন্ত যায়নি)
s.erase(it); // ইটারেটর দিয়ে ডিলিট করা হলো
}
// টিপস: সরাসরি ভ্যালু দিয়েও ডিলিট করা যায়: s.erase(1);
Count (0 or 1)
সেটে যেহেতু ডুপ্লিকেট থাকে না, তাই count() ফাংশনটি শুধুমাত্র 0 (নেই) অথবা 1 (আছে) রিটার্ন করে। এটি চেক করার সবচেয়ে সহজ উপায়।
if (s.count(5)) {
cout << "5 is present\n";
}
Lower/Upper bound
কম্পিটিটিভ প্রোগ্রামিংয়ে বাইনারি সার্চের কাজ সহজে করার জন্য এই দুটি ফাংশন জাদুর মতো কাজ করে।
- lower_bound(x): সেটের এমন প্রথম সংখ্যাটি ইটারেটর হিসেবে দেয় যা x এর সমান বা বড় (>=x)।
- upper_bound(x): সেটের এমন প্রথম সংখ্যাটি ইটারেটর হিসেবে দেয় যা x এর চেয়ে বড় (>x)।
// মনে করি, s = {2, 4, 6, 8, 10}
auto it1 = s.lower_bound(4); // ৪ এর সমান বা বড় কে? ৪ নিজেই। (Points to 4)
auto it2 = s.upper_bound(5); // ৫ এর চেয়ে বড় কে? ৬। (Points to 6)
10) multiset — Sorted, Duplicates allowed
multiset ঠিক set -এর মতোই কাজ করে (সবসময় সর্টেড থাকে), কিন্তু এর মূল পার্থক্য হলো এতে একই মান একাধিকবার (Duplicates) রাখা যায়।
multiset<int> ms;
ms.insert(1);
ms.insert(1); // আবার ১ রাখলাম (Duplicate allowed)
ms.insert(6);
ms.insert(7);
ms.insert(9);
ms.insert(4);
// বর্তমানে ms: {1, 1, 4, 6, 7, 9}
cout << ms.count(1) << "\n"; // Output: 2 (কারণ দুইটা ১ আছে)
Erase one occurrence (IMPORTANT)
মাল্টিসেট ব্যবহার করার সময় সবচেয়ে বড় ভুলটি হয় ডিলিট করার সময়।
- ভুল পদ্ধতি: যদি
ms.erase(1)লেখা হয়, তবে সেটি সেটের সবগুলো ১ মুছে ফেলবে।
সঠিক পদ্ধতি (একটি মুছতে চাইলে): শুধু একটি ১ ডিলিট করতে, তবে প্রথমে find() দিয়ে তার ইটারেটর বের করতে হবে এবং সেই ইটারেটর দিয়ে ডিলিট করতে হবে।
// সব '1' মুছে ফেলবে
// ms.erase(1);
// শুধুমাত্র একটি '1' মুছতে চাইলে
auto it = ms.find(1); // প্রথম '1' খুঁজে বের করবে
if (it != ms.end()) {
ms.erase(it); // ইটারেটর ব্যবহার করলে শুধু ওই পজিশনের ভ্যালু মুছবে
}
cout << ms.count(1) << "\n"; // Output: 1 (এখন একটা ১ বাকি আছে)
11) unordered_set — Hash set (average O(1))
set ডাটাগুলোকে সর্টেড বা সাজানো অবস্থায় রাখে, কিন্তু unordered_set কোনো নির্দিষ্ট ক্রম বা অর্ডার মেনে চলে না। এটি এলোমেলোভাবে ডাটা রাখে। এটি ইন্টারনালি Hash Table ব্যবহার করে।
unordered_set<int> us;
us.insert(5);
us.insert(1);
us.insert(10);
// অর্ডার র্যান্ডম হতে পারে, যেমন: {1, 10, 5}
cout << us.count(5) << "\n"; // Output: 1 (আছে)
set বনাম unordered_set
| বৈশিষ্ট্য | set | unordered_set |
|---|---|---|
| অর্ডার | সবসময় সর্টেড (Sorted) | এলোমেলো (Random) |
| ইমপ্লিমেন্টেশন | Balanced BST (Tree) | Hash Table |
| Time Complexity | O(log N) | Average O(1) |
সতর্কতা (Worst Case) সাধারণত unordered_set খুব দ্রুত (O(1)) কাজ করে। কিন্তু মনে রাখতে হবে, এর Worst Case টাইম কমপ্লেক্সিটি হলো O(N)। বিশেষ করে Codeforces -এর মতো প্ল্যাটফর্মে "Hash Collision" ঘটিয়ে কোড স্লো করে দেওয়ার বা হ্যাক করার সম্ভাবনা থাকে। তাই অর্ডার প্রয়োজন না হলে এটি ব্যবহার করা উচিত, কিন্তু TLE (Time Limit Exceeded) এড়াতে সতর্ক থাক হয়।
12) map — Sorted key->value
ম্যাপ (Map) হলো এমন একটি ডাটা স্ট্রাকচার যা ডাটাকে Key এবং Value এর জোড়া হিসেবে সংরক্ষণ করে। একে আপনি একটি ডিকশনারির সাথে তুলনা করতে পারেন—যেখানে "Word" হলো Key এবং "Meaning" হলো Value।
ম্যাপের দুটি প্রধান বৈশিষ্ট্য: ১. প্রতিটি Key ইউনিক বা অদ্বিতীয় হতে হয়। ২. ম্যাপে ডাটাগুলো সবসময় Key অনুয়ায়ী সর্টেড থাকে।
map<string, int> mp;
// ১. ডাটা রাখা (Insert)
mp["labib"] = 10;
mp["hasan"] = 20;
// লজিক: "labib" নামের (Key) বিপরীতে ১০ (Value) জমা হলো।
Access / Exists
ম্যাপ থেকে ভ্যালু দেখার জন্য আমরা অ্যারের মতো [] ব্র্যাকেট ব্যবহার করি। তবে এখানে একটি বড় সতর্কতা আছে।
cout << mp["labib"] << "\n"; // Output: 10
// সতর্কতা: যদি এমন কোনো Key খোঁজেন যা ম্যাপে নেই,
// তবে ম্যাপ সেই Key টি তৈরি করে ভ্যালু হিসেবে ০ বসিয়ে দেয়!
cout << mp["unknown"] << "\n"; // Output: 0 (অটোমেটিক তৈরি হয়ে গেছে)
কোনো Key আছে কি না তা চেক করার জন্য count() ব্যবহার করা নিরাপদ।
cout << mp.count("x") << "\n"; // 0 (নেই) অথবা 1 (আছে)
Safe read (no auto-create)
অপ্রয়োজনীয় Key তৈরি হওয়া আটকাতে find() ব্যবহার করা সবচেয়ে ভালো অভ্যাস।
auto it = mp.find("x");
if (it != mp.end()) {
// যদি পাওয়া যায়
cout << it->second << "\n"; // Value প্রিন্ট হবে
} else {
cout << "Key not found\n";
}
Iterate
ম্যাপের ওপর লুপ চালালে আমরা প্রতিটি পেয়ার (pair) পাই। এখানে .first হলো Key এবং .second হলো Value।
for (auto &kv : mp) {
cout << kv.first << " -> " << kv.second << "\n";
}
Time Complexity: ম্যাপ ইন্টারনালি Balanced BST ব্যবহার করে, তাই ইনসার্ট, ডিলেট এবং সার্চ সব কিছুই O(logN) সময়ে হয়।
13) unordered_map — Hash map (average O(1))
map ডাটাগুলোকে কি (Key) অনুযায়ী সাজিয়ে রাখে, কিন্তু unordered_map কোনো নির্দিষ্ট ক্রম মেনে চলে না। এটি ইন্টারনালি Hash Table ব্যবহার করে, তাই এটি সাধারণ ম্যাপের চেয়ে অনেক দ্রুত কাজ করে।
unordered_map<string, int> ump;
ump["labib"] = 7;
ump["hasan"] = 5;
// প্রিন্ট করলে কোন অর্ডারে আসবে তা নিশ্চিত নয়
map বনাম unordered_map:
| বৈশিষ্ট্য | map | unordered_map |
|---|---|---|
| অর্ডার | সর্টেড (Sorted) | এলোমেলো (Random) |
| টাইম কমপ্লেক্সিটি (Average) | O(log N) | O(1) |
| টাইম কমপ্লেক্সিটি (Worst) | O(log N) | O(N) |
সতর্কতা:
সাধারণত unordered_map ম্যাপের চেয়ে দ্রুত কাজ করে। তবে মনে রাখতে হবে, এর Worst Case কমপ্লেক্সিটি হলো O(N)। কম্পিটিটিভ প্রোগ্রামিংয়ে (যেমন Codeforces) "Hash Collision" ঘটিয়ে হ্যাক করার মাধ্যমে আপনার সলিউশনকে TLE (Time Limit Exceeded) খাওয়ানো সম্ভব। তাই যদি সর্টেড অর্ডারের প্রয়োজন না হয় এবং সাধারণ প্রবলেম সলভিং করেন, তবে এটি ব্যবহার করতে পারেন। তবে কনটেস্টে সেফ থাকার জন্য অনেকে map বা কাস্টম হ্যাশ ব্যবহার করেন।
14) multimap — Sorted, duplicate keys allowed
সাধারণ ম্যাপে একটি Key মাত্র একবারই থাকতে পারে। কিন্তু multimap -এ একই Key একাধিকবার রাখা যায়। এটিও ডাটাকে Key অনুযায়ী সর্টেড বা সাজানো অবস্থায় রাখে।
সতর্কতা: multimap -এ mp["key"] বা থার্ড ব্র্যাকেট অপারেটর কাজ করে না। ডাটা রাখার জন্য অবশ্যই insert ফাংশন ব্যবহার করতে হয়।
multimap<int, string> mm;
mm.insert({1, "a"});
mm.insert({1, "b"}); // একই Key '1' আবার রাখা হলো
mm.insert({2, "x"});
// mm এখন: { (1, "a"), (1, "b"), (2, "x") }
Range of same key
যেহেতু একই Key- এর অনেক ভ্যালু থাকতে পারে, তাই নির্দিষ্ট কোনো Key- এর সব ভ্যালু পাওয়ার জন্য equal_range() ফাংশন ব্যবহার করা হয়। এটি একটি পেয়ার (Pair) রিটার্ন করে— যার প্রথমটি হলো রেঞ্জের শুরু এবং দ্বিতীয়টি হলো রেঞ্জের শেষ।
// Key '1' এর সব ভ্যালু বের করা
auto range = mm.equal_range(1);
for (auto it = range.first; it != range.second; ++it) {
cout << it->first << " " << it->second << "\n";
}
// Output:
// 1 a
// 1 b
16) Time Complexity Quick Table
| Structure | Insert | Find / Access | Erase | Order |
|---|---|---|---|---|
| vector (end) | O(1) | O(1) / O(n) | O(n) | keeps order |
| vector (middle) | O(n) | O(n) | O(n) | keeps order |
| deque | O(1) (ends) | O(1) / O(n) | O(n) | keeps order |
| list | O(1) | O(n) | O(1) | keeps order |
| forward_list | O(1) | O(n) | O(1) | keeps order |
| stack | O(1) | top O(1) | pop O(1) | LIFO |
| queue | O(1) | front O(1) | pop O(1) | FIFO |
| priority_queue | O(log n) | top O(1) | pop O(log n) | by priority |
| set | O(log n) | O(log n) | O(log n) | sorted |
| multiset | O(log n) | O(log n) | O(log n) | sorted |
| map | O(log n) | O(log n) | O(log n) | sorted |
| multimap | O(log n) | O(log n) | O(log n) | sorted |
| unordered_set | avg O(1) | avg O(1) | avg O(1) | random |
| unordered_multiset | avg O(1) | avg O(1) | avg O(1) | random |
| unordered_map | avg O(1) | avg O(1) | avg O(1) | random |
| unordered_multimap | avg O(1) | avg O(1) | avg O(1) | random |
শেষ কথা
STL-এর প্রতিটি container আর function- এর আলাদা আলাদা ব্যবহার আছে। সব জায়গায় একটাই container ব্যবহার করলে অনেক সময় কোড ধীর হয়ে যায় বা অপ্রয়োজনীয় মেমোরি খরচ হয়। তাই প্রোগ্রাম লেখার সময় আগে ভাবা দরকার এই সমস্যার জন্য কোন container সবচেয়ে ভালো হবে, আর কোন operation বেশি ব্যবহার হবে। এই cheatsheet- টা মূলত রিভিশন আর দ্রুত রেফারেন্সের জন্য বানিয়েছি।
আশা করি এটা সবার কাজে লাগবে। সবচেয়ে গুরুত্বপূর্ণ কথা হলো- শুধু মুখস্থ না করে নিয়মিত প্র্যাকটিস করো, নিজে কোড লিখে ভুল করো,আর সেখান থেকেই শেখার চেষ্টা করো। ধীরে ধীরে অভ্যাস হলে STL তোমার জন্য অনেক সহজ হয়ে যাবে।
মতামত দিন
এই লেখা কেমন লাগলো? ভুল/পরামর্শ লিখে পাঠান।